Term Frequency (TF)¶
What is Term Frequency?¶
Imagine you're looking for a book article on WordPress. The more WordPress appears in the doucment suggests the more relevant the query term WordPress is.
Term Frequency (TF) = How many times a query word appears in a document
Simple Term Frequency:
term === word
TF = (number of times term appears in document) / (total number of terms in document)
Example:
Document: "the cat sat on the mat"
- Total terms: 6
- Query term "cat" appears: 1 times
- TF("the") = 1/6 = 0.167
Why normalize by document length?
Without dividing by total terms, longer documents would always score higher just because they have more words. Normalizing makes it fair - a term appearing 2 times in a 10-word doc (20%) is more significant than 2 times in a 1000-word doc (0.2%).
Essentially, we are interested in the density or concentration of term in a document not just the abolute number of times it occurs.
Limitation:
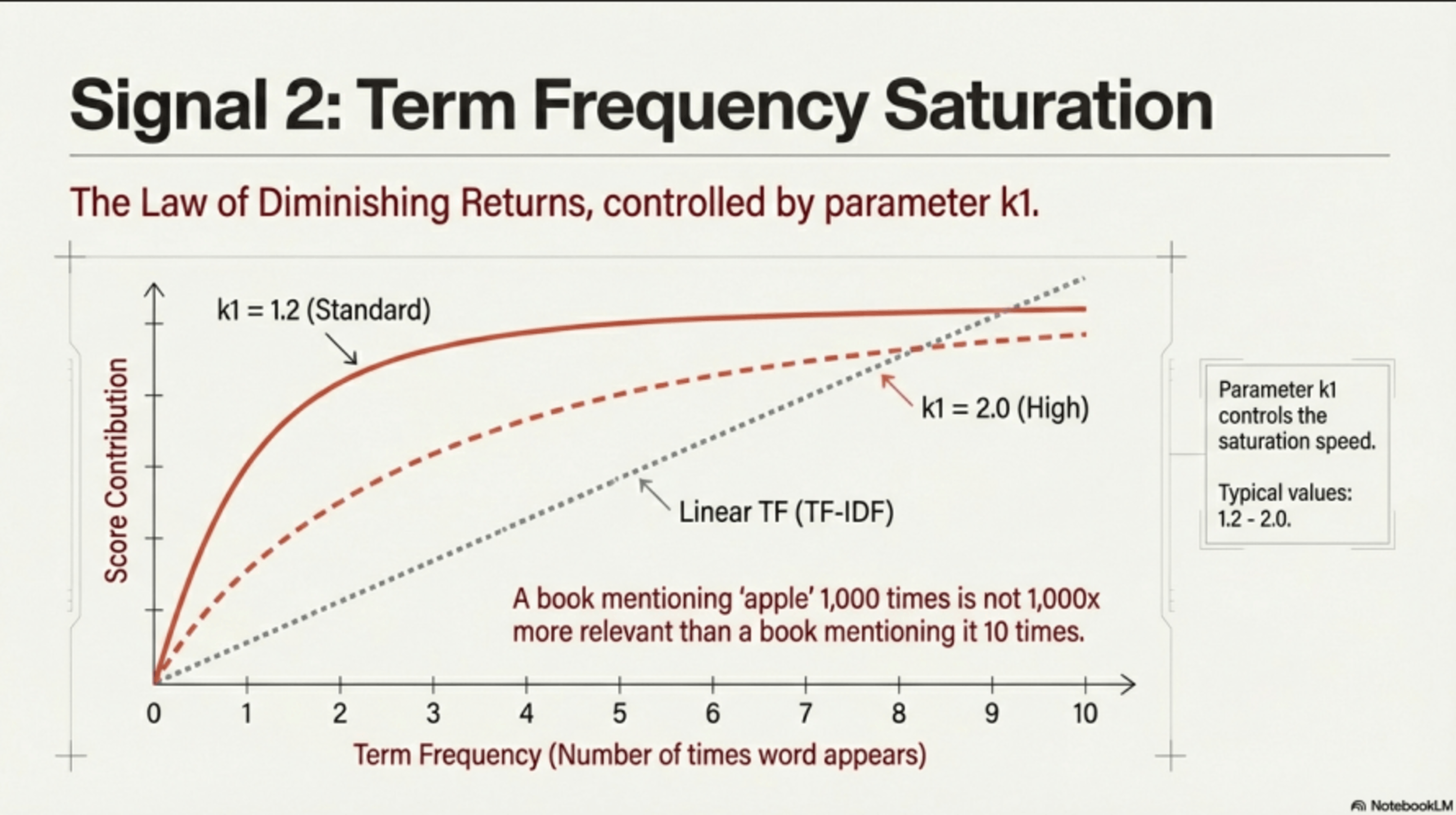
TF treats the 1st and 100th occurrence equally. That's why most search systems use something like BM25 instead, which adds diminishing returns.
(We will see the k1 parameter that dampens key word saturation later).
Visual Comparison¶
Document A: "dog dog dog cat"
🐕🐕🐕🐱
TF(dog) = 3/4 = 0.75
Document B: "dog cat cat cat"
🐕🐱🐱🐱
TF(dog) = 3/4 = 0.25
Problem¶
Please note, the terms k1 and b will be explained fully in BM25.
The key for this graphic is we need to avoid 'stuffing' or 'key word satiration' distroting the relevancy - and for document length with parameter 'b'.
What about 'word stuffing'? A good document with a lower TF should rank higher than a poor document with word stuffing.
Quick Summary¶
- Higher TF = Word appears more often = Probably more relevant
- Lower TF = Word appears less often = Probably less relevant
- Formula: TF = (Word count in doc) / (Total words in doc)
- Used in: Search engines, recommendation systems, text analysis